これでデータの解析が可能となりましたが,ヒストグラムには問題があります...
まずは,binの範囲,そのものの値です.
たとえば,binの範囲を,
0-1
1-2
2-3
...
とします.
すると,
0.5は0-1,1.2は1-2の範囲に入ります.
この際の表示は,アプリにもよりますが,
0,1,2...もしくは,1,2,3...
となってしまいます.
しかし,正しくはその範囲の平均値ですので,
0.5, 1.5, 2.5...
です.
ここをちゃんとチェックしないとデータ自体が横軸にずれてしまいます.
次の問題はbinの大きさの設定の仕方です.
一般的に適当にbinをいじって,一番見栄えのいい結果を採用するのが人の心理です.
しかし,そうなると,”主観”が入ってしまうわけです.
サイエンスはできるだけ客観的にデータを解析しなくてはならないのですが,ヒストグラムを作成すること自体に主観が入ってしまいます.
データ量が多く,理想的な結果ならあまり問題はありませんが,実験結果は必ずしもそうではありません.
ですから,いかに客観的にデータを解析するかがサイエンスの鍵となります.
さらに問題が...
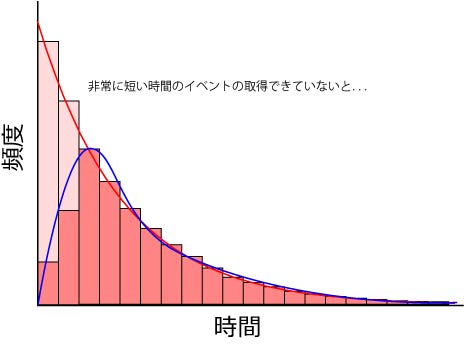
それは短いイベントを果たしてきちんと取得しているか,という問題です.
アンサンブル平均の場合,しかも単純な指数関数の減少の場合,非常に短い時間のイベントが大量に存在するはずです.
しかし,装置の時間分解能の限界などから,それら短いイベントをとらえられない場合が少なくありません.
するとどうなるでしょう?
一次反応の場合,ヒストグラムをとると,短いイベントの取得数が減るため,実際には単純な指数関数の減少なのに,左側のイベントが少なくなり,あたかも真ん中にピークを持つカーブとなってしまいます.
まるで,二つの指数関数の差のモデルのように....
では,これらの結構シリアスな問題をどう改善したらよいでしょう?
![]()
![]()
![]()